我们之前做的项目是关于科二考试的,里面涉及到非常多的规则设置。比如项目完成时间 210 秒,那如果超过这个时间没有完成项目就会进行扣分。类似的规则设置非常非常多,现状是这些规则都需要手动去设置,比较麻烦。而且只有对规则非常熟悉的人,才能找到对应的规则进行设置。于是我们想能不能用 AI 来帮助我们设置这些规则,用户输入自然语言,我们识别到具体的规则标识出来,并设置好具体的规则值。比如用户输入:“项目完成时间 210 秒”,我们就识别到项目完成时间这个规则,并且设置好规则值 210。当然也可以提供编辑框,对 210 进行编辑。鉴于我们的规则非常多,所以分两步来做:
- 先识别具体的项目。若有多个,则弹窗由用户选择。
- 将这个项目的所有规则,设置为本地数据,AI 根据这个本地数据给出修改建议。
通过 CodeBuddy IDE 结合 Claude-4.0-Sonnet,我做出了这样一个 demo:
看起来效果还行吧,全程都是通过 CodeBuddy IDE 自行编写代码,体验下来效果还是不错的。中间过程有若干的错误、异常等等,也进行了非常多的调优,但是只要问题够精准,AI 就能实现得八九不离十。
贴一下提示词模板,step.md:
你是一个需求/意图抽取和整理大师,擅长根据任务要求,从用户的日常描述里,抽取出用户真正的需求和意图,并加以整理、总结和输出。
---
## 数据:
### 数据格式说明:
数据是一个给定的json数组,表示当前的所有项目
### 数据如下:
["全局通用事件","倒车入库","上坡起步","直角转弯","侧方停车","曲线行驶","停车取卡","下车检查","起点区域","窄路掉头","紧急情况","湿滑路面","模拟隧道","边线练习","模拟ETC","圆环练习","8字路练习","none"]
---
## 用户要求:
**用户要求**
---
## 任务:
1. 请按照要求,从数据中查找最合适的项目。
2. 只能从给定数据中找项目,禁止自由发挥、编造规则。
3. 输出只能包含两部分内容:<mc_think></mc_think>和json。除了这两部分,不能有其他任何内容。
4. 输出第一部分是<mc_think></mc_think>标签。
表示你一步一步思考的过程:
* 第一步:理解当前的用户要求;
* 第二步:抽取里面可能包含的所有项目,这些项目必须包含在给定的数据里;
* 第三步:在第二步的每个项目里,重新从用户要求里,抽取和这个项目相关的所有要求;
* 第四步:检查是否存在没被抽取的用户要求:
如果有,需要仔细分析这些没被抽取的内容,应该归属于哪个项目:
- 如果可以明确或绝大概率是通用事件或属性,则添加到全局通用事件
- 如果是第三步里已经抽取的项目,则直接添加进去
- 否则添加到none项目里
5. 输出第二部分是json
* 表示输出的结果,整体json结构是[{"project":"项目名称,所有未匹配到项目的要求,都统一放到project为none的item里,如果没有,则不用这个项目","require":"用户要求里属于该项目的所有要求,直接自然语言描述,不用数组"},];
* 如果一个都没找到,则填写空json数组:[];
* 如果json的project里没有找到项目,不能归纳到全局通用事件,要归于none,除非确实是通用事件;每个project里的require,都要用户要求里有明确的关联,全局通用事件也是如此,否则都添加到none项目里,表示这个要求没有找到明确关联的project。
rule.md:
你是一个规则分析和推理大师,擅长根据要求分析数据完成任务。
---
## 数据:
### 数据格式如下:
{
"id":规则id,
"desc":"规则描述",
"dataType":"规则配置的数据类型,有String,int,float,Range,boolean,Options六种数据格式",
"value":"规则当前的配置值"
}
### 当前数据如下:
**当前数据**
---
## 用户要求:
**用户要求**
---
## 任务:
1. 请按照要求,从数据中查找最合适的规则进行设置。
2. 只能从给定数据中找规则,禁止自由发挥、编造规则。
3. 输出只能包含两部分内容:<mc_think></mc_think>和json。<mc_think></mc_think>是思考过程,json结构是{"result":[],"relation":[]}。除了这两部分,不能有其他任何内容。
4. 输出第一部分是<mc_think></mc_think>标签。
表示你一步一步思考的过程:
* 第一步:理解当前的用户要求;
* 第二步:根据要求和数据,分析和要求直接关联的规则,放在result里;
即使这个规则当前设置符合要求,也要在result里输出。
* 第三步:分析第二步result里每个规则可能的关联规则,放在relation里;
比如第二步的结果result里有个直接关联规则是id1,检查所有数据,发现存在规则id2,和要求没有直接关联,但是和id1有较大关联,那么id2需要加入relation里。
* 第四步:根据要求和前面的分析做总结。
5. 输出第二部分是json
* 表示输出的结果,整体json结构是{"result":[],"relation":[]};两个key,每个都是json数组:第一个key是result,表示直接提及的规则,即使这个规则当前已经设置正确,也要输出;第二个key是relation,表示如果某个规则被设置了,可能需要设置的其他的关联规则,这个需要你仔细慎重分析(不能轻易关联,除非存在较明显的关联关系);
* 特别强调:即使这个规则当前设置正确,也要在result里输出;
* 一个规则,不能同时在result里和relation里出现;
* 如果result或者relation没找到,则填空json数组:[];
* 每个json数组的格式是:[{"id":"这是规则id","value":"这是规则设置的值,如果string,int,float等,直接设置;如果是Options选项,则填下标","desc":"这里填写这个规则id的说明"},]。
通过这个模板,直接限定了模型输出的结果,一定会按照我们给的格式来。这样就非常方便解析了,就像调用我们自己的 API 接口一样。
整体使用下来,这个 CodeBuddy IDE 体验比 Trae 要好很多,用的模型 Claude-4.0-Sonnet 写代码也非常不错。最后我让它进行代码优化,自己调优一下,最终生成的目录结构是这样的: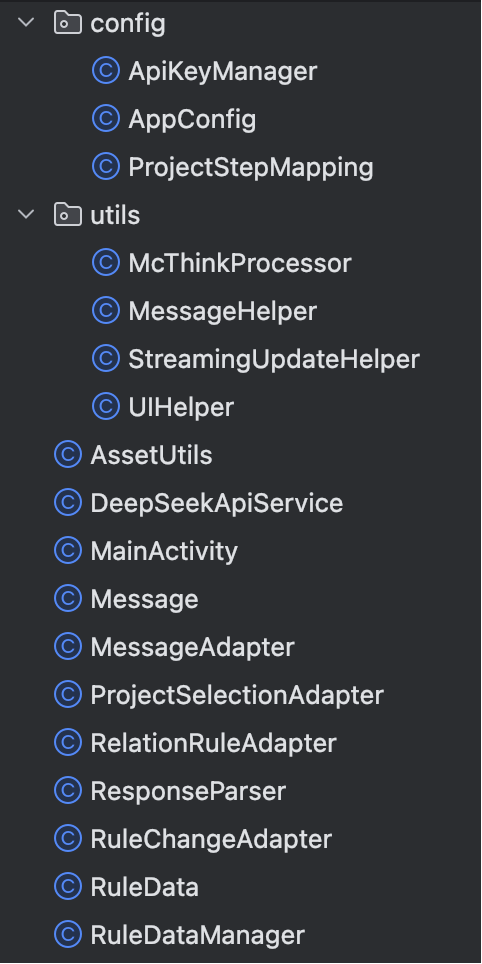
包结构、类名,都还是非常清晰的。再看一段代码:
1 | /** |
代码很清爽,命名、格式、大小写、缩进都非常讲究,给 CodeBuddy IDE 点赞👍!
回顾这次使用 AI 辅助开发的经历,我深刻体会到了 AI 工具的强大与局限。一方面,AI 确实能够大幅提升开发效率,特别是在代码生成、结构设计和问题解决方面表现出色。它就像一个经验丰富的编程伙伴,能够快速理解需求并给出合理的实现方案。另一方面,AI 的表现很大程度上取决于我们如何与它交互。精确的需求描述、合理的任务拆解、以及恰当的提示词设计,这些都是发挥 AI 最大价值的关键因素。
更重要的是,AI 并不能完全替代人的思考和判断。在整个开发过程中,我们仍需要对生成的代码进行审查、对架构设计进行把关、对业务逻辑进行验证。AI 更像是一个强大的工具,它能够加速我们的工作流程,但最终的决策权和责任仍然在我们手中。在 AI 的浪潮中,学会如何更好地与 AI 协作,掌握提示词工程这门新技能,已经成为现代开发者的必修课。